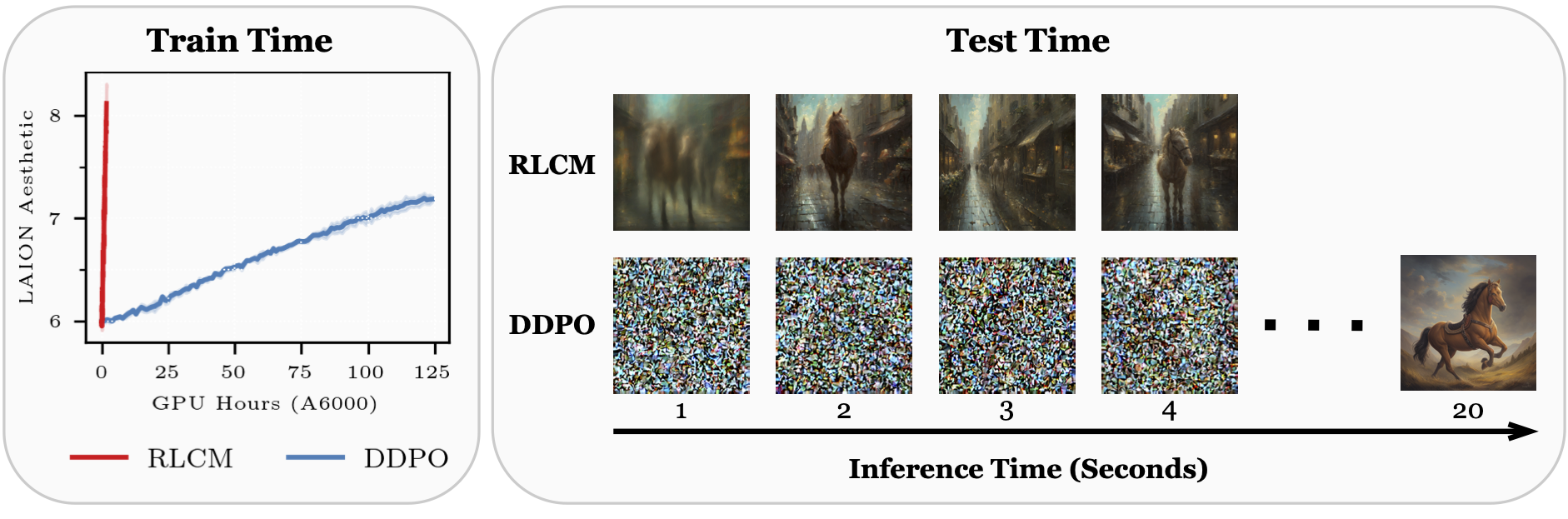
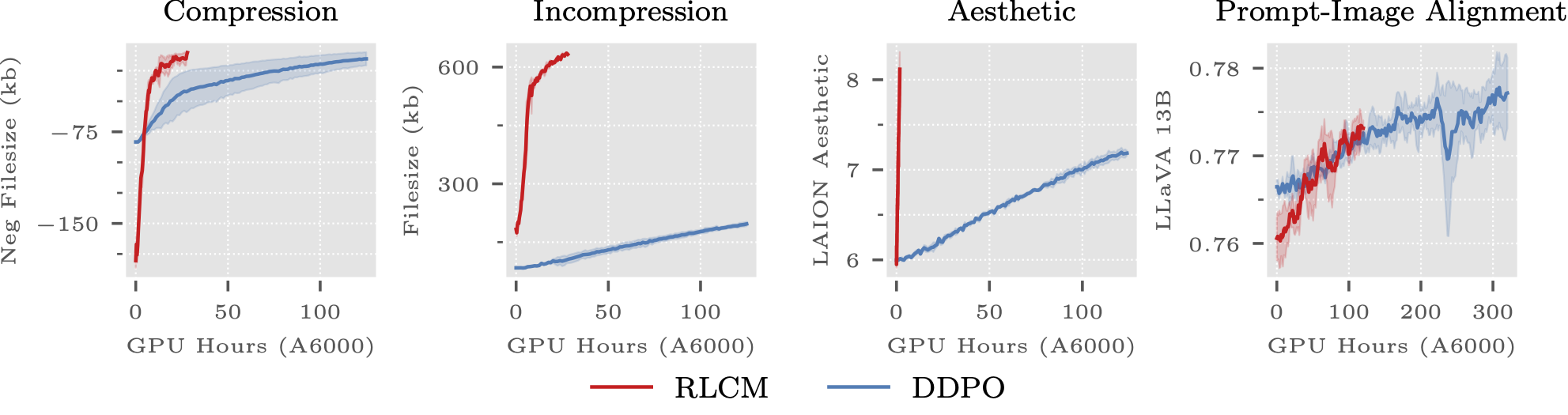
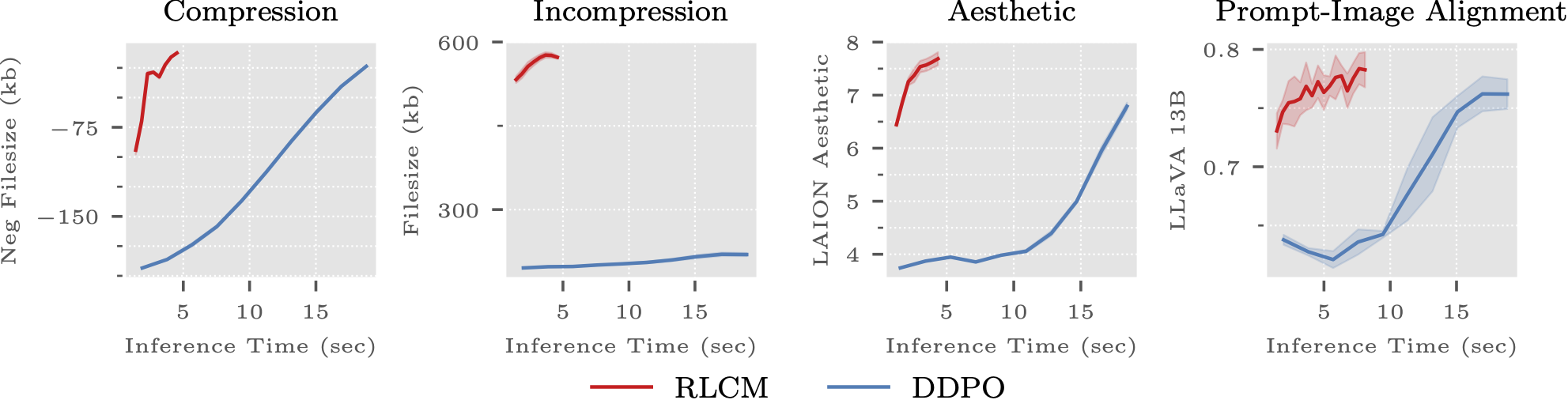
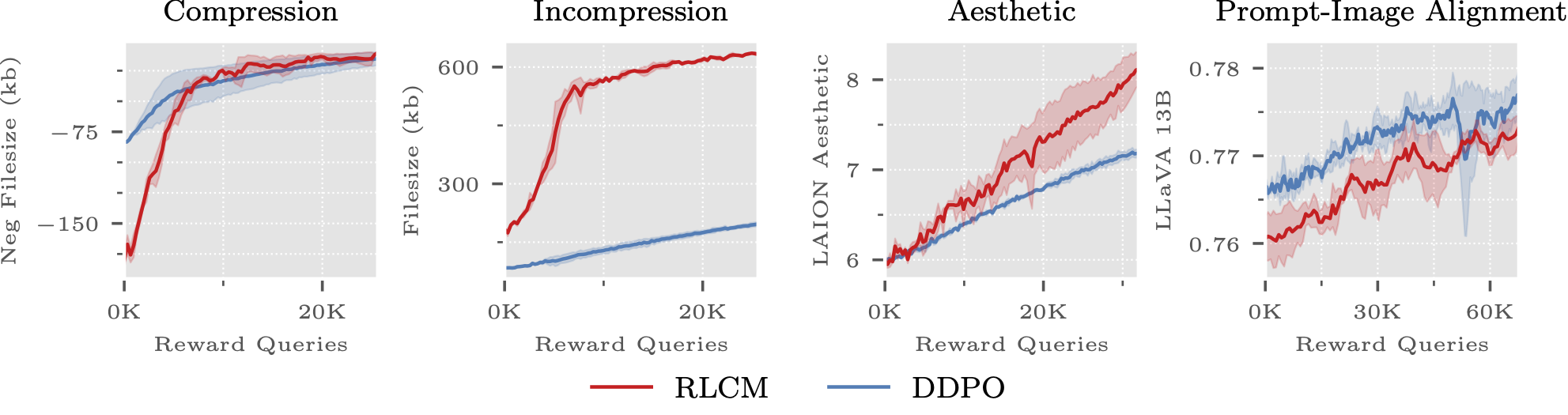


@misc{oertell2024rl,
title={RL for Consistency Models: Faster Reward Guided Text-to-Image Generation},
author={Owen Oertell and Jonathan D. Chang and Yiyi Zhang and Kianté Brantley and Wen Sun},
year={2024},
eprint={2404.03673},
archivePrefix={arXiv},
primaryClass={cs.CV}
}